Use Shadeform with ECS Anywhere
By Ronald Ding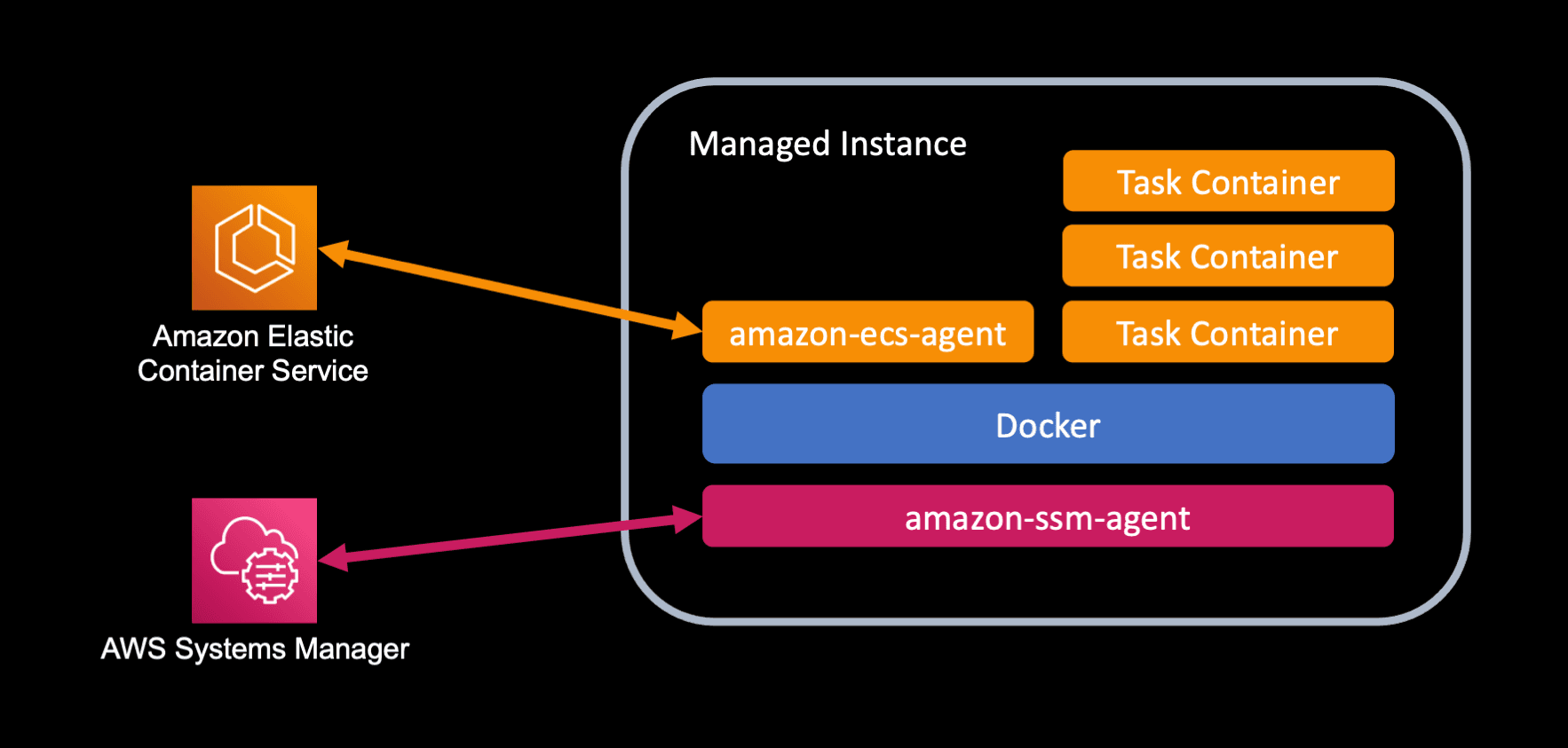
You can use Shadeform to deploy GPU instances in 15+ providers! With so many Shadeform instances, how can you manage them as a cluster?
One solution for cluster management is using AWS’s Elastic Container Service (ECS) Anywhere for a serverless experience.
In this guide, you'll learn:
- How to set up an ECS cluster for ECS Anywhere
- How to add Shadeform instances into the cluster
- How to run a GPU powered Jupyter Notebooks for ML development
- How to run a vLLM inference server
Create ECS Cluster
- To start off, go to the AWS console and find the ECS service page using the search bar.
- Next click on “Create Cluster” to create a new ECS cluster.
- On the creation form, give the cluster the name “shadeform-ecs-anywhere”.
- Under “Infrastructure”, make sure that “AWS Fargate (serverless)” is checked and “Amazon EC2 instances” is NOT checked.
- Wait for the ECS Cluster to become active
Create Shadeform Instance
- Follow this quickstart guide to create an instance in Shadeform.
- Alternatively, create a shadeform instance using the shadeform console at https://platform.shadeform.ai/.
- Wait for the Shadeform instance to become active.
Get the ECS Anywhere Registration Command
- Once the ECS Cluster is active, click on the cluster name “shadeform-ecs-anywhere”.
- Scroll down and click on the “Infrastructure” tab.
- Scroll down to the “Container instances” table and click on the button “Register External Instances”
- Click on “Generate registration command”.
- In the “Linux Command” section, click on the “Copy” button to retrieve your registration command.
[IMPORTANT] This command is not the complete command, you will need to append “ --enable-gpu” to the command to enable GPU access.
curl --proto "https" -o "/tmp/ecs-anywhere-install.sh" "https://amazon-ecs-agent.s3.amazonaws.com/ecs-anywhere-install-latest.sh" && bash /tmp/ecs-anywhere-install.sh --region "<region>" --cluster "shadeform-ecs-anywhere" --activation-id "<activation_id>" --activation-code "<activation_code>" —enable-gpu
Install ECS Anywhere Agent on the Shadeform Instance
- Once the Shadeform instance is active, you can ssh into the Shadeform instance using the command:
ssh -i <path_to_private_key.pem> shadeform@<ip>
- [IMPORTANT] Once you are SSH’d into the machine, you must run the registration command using an elevated shell by running “sudo su”.
-
[IMPORTANT] After entering the elevated shell, paste in the copied registration command with the appended “ --enable-gpu” to the command. If you do not append “ --enable-gpu”, the GPUs on the machine will not be recognized.
-
Run the command and wait for the command to succeed.
- If everything is installed correctly, you can now return to the ECS page on the AWS console and see that a new row has been added to the “Container instances”. This row represents the new instance that you just added to your ECS cluster!
- You may repeat these steps to add more instances to your cluster for orchestration.
Create Jupyter Notebook Task Definition
A task definition is the definition of a specific resource to be run on the ECS cluster.
In Kubernetes terms, this would be the equivalent of a Pod.
- On the AWS console for ECS, click on “Task definitions” on the sidebar.
- Click on the “Create new task definition” button which opens a drop down. In the dropdown, select “Create new task definition with JSON”.
- Paste in the Jupyter Notebook task definition below.
{
"containerDefinitions": [
{
"name": "jupyter",
"image": "quay.io/jupyter/pytorch-notebook:cuda12-python-3.11.8",
"portMappings": [
{
"containerPort": 8888,
"hostPort": 8888,
"protocol": "tcp"
}
],
"essential": true,
"resourceRequirements": [
{
"value": "1",
"type": "GPU"
}
]
}
],
"family": "jupyter-notebook",
"executionRoleArn": "<YOUR_EXECUTION_ROLE_ARN>",
"networkMode": "host",
"requiresCompatibilities": [
"EXTERNAL"
],
"cpu": "10240",
"memory": "32768",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
}
}
- Make sure to substitute the executionRoleArn with your own executionRoleArn.
- If you need help creating an executionRole, go back to the “Task definitions” page and click on the “Create new task definition” button (this time with the JSON) and fill out the form with any values. It will automatically create a new execution role on your behalf that you can use for this task.
- Modify the “value” of resourceRequirements array object where type is “GPU” to your desired GPU count.
- Click “Create” to save the task definition.
- After the task definition is created, click on “Clusters” in the sidebar to go back to the clusters page and click on “shadeform-ecs-anywhere” to return to your cluster.
Run the Jupyter Notebook Container on the Shadeform Instance
- Click on the “Task” navbar item and click on “Run New Task”.
- On the new page, click on “Launch type”.
- On the “Launch type” dropdown that appears, select “EXTERNAL”.
- Scroll down to the “Deployment Configuration” section. In this section, select “Task”.
- Under the “Family” dropdown, select “jupyter-notebook” and under the “Revision” dropdown, select the latest revision.
- Scroll down to the bottom and hit “Create”.
Access Jupyter Notebook
- Go back to “Clusters” on the sidebar, select the “shadeform-ecs-anywhere” cluster, and then go to the “Tasks” navbar item.
- Wait until the new task is active.
- Once the task is active, click on the task link and then go to the “Logs” tab. You will see your container logs here being piped into an AWS CloudWatch log group.
- In the container logs, find the line that says “
http://127.0.0.1:8888/lab?token=<token>” - Go to “
http://<ip>/lab?token=<token>” where IP is your Shadeform instance IP and the token is the token retrieved from the logs.
- You should now be able to access the Jupyter Notebook!
Create vLLM Task Definition
- Follow the same steps as above for creating the vLLM task definition.
{
"containerDefinitions": [
{
"name": "vllm",
"image": "vllm/vllm-openai:latest",
"portMappings": [
{
"containerPort": 8000,
"hostPort": 8000,
"protocol": "tcp"
}
],
"essential": true,
"command": [
"--model",
"HuggingFaceH4/zephyr-7b-beta"
],
"resourceRequirements": [
{
"value": "4",
"type": "GPU"
}
]
}
],
"family": "vllm",
"executionRoleArn": "<YOUR_EXECUTION_ROLE_ARN>",
"networkMode": "host",
"requiresCompatibilities": [
"EXTERNAL"
],
"cpu": "10240",
"memory": "32768",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
}
- In the task definition, add the additional command arguments with the model that you want to deploy. If the model that you want to deploy is gated, make sure to add an environment variable section with your hugging face hub token.
Query vLLM Server
Once the task becomes active and the model is fully downloaded in vLLM, you can now query the completions API for inference!